I just finished a project where I built a neural network from scratch to classify handwritten digits using the MNIST dataset. The model is simple — four fully-connected layers, no convolutions, no dropout. But the two training runs I did told me more about deep learning fundamentals than the architecture itself.
The Model
The network is a straightforward MLP:
784 → 256 → 128 → 64 → 10Each hidden layer uses ReLU activation, and the output uses log softmax paired with negative log-likelihood loss. The input is a flattened 28x28 grayscale image, and the output is a probability distribution over digits 0–9.
Nothing fancy — I wanted to see how far a simple architecture could go.
Run 1: Learning Rate 0.01
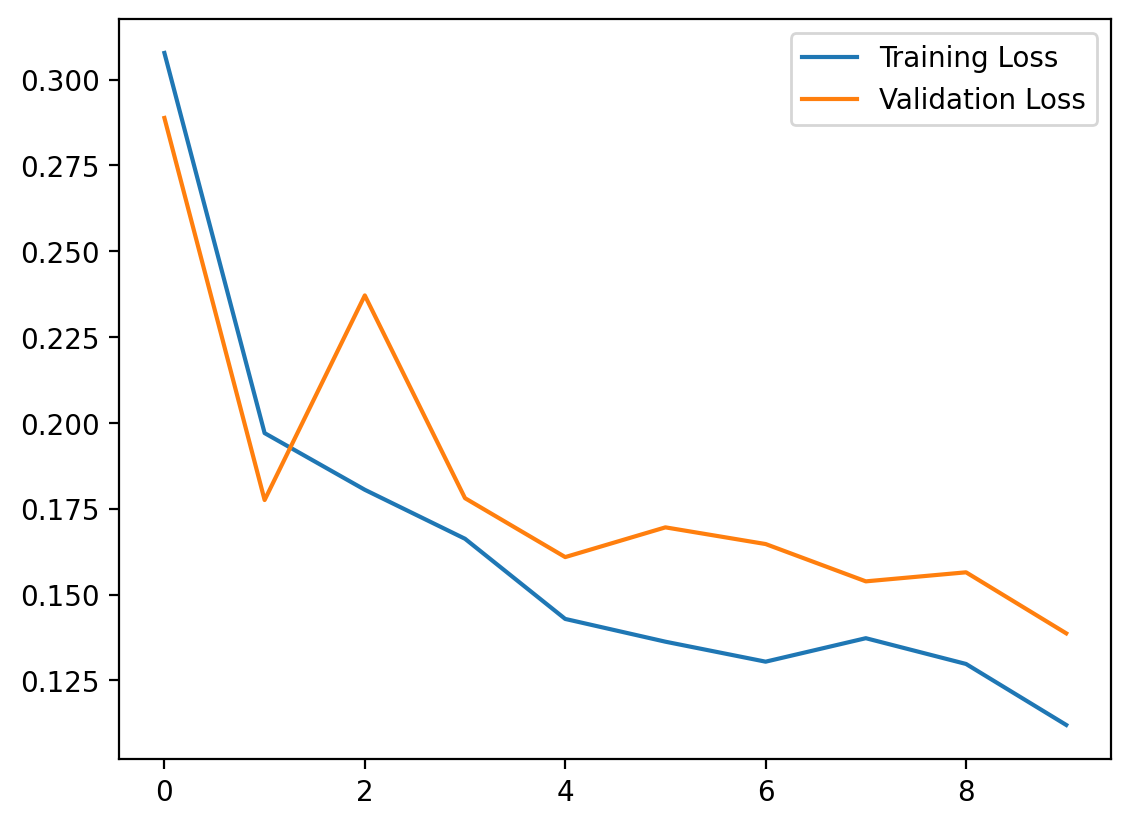
My first instinct was to use a learning rate of 0.01 with Adam and train for 10 epochs. The model converged and hit 97.02% accuracy on the test set. Not bad for a simple MLP.
But the loss curves told a different story. Validation loss was erratic — it spiked to 0.2371 at epoch 3 despite training loss steadily decreasing. The model was learning, but it was overshooting on each update, bouncing around the loss landscape instead of settling into a minimum.
Run 2: Learning Rate 0.0001
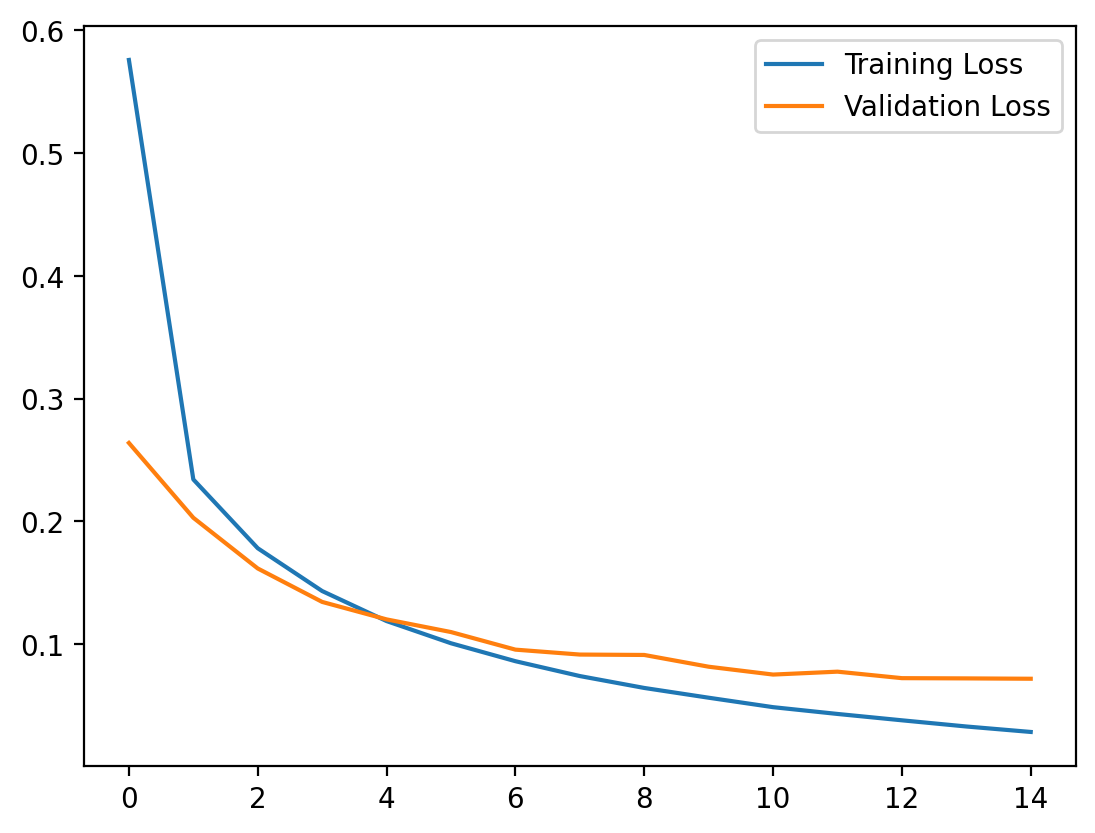
For the second run, I dropped the learning rate to 0.0001 and extended training to 15 epochs. The result: 97.74% accuracy — a modest improvement in the headline number, but a dramatic difference in training behavior.
The loss curves were smooth. Training loss and validation loss decreased together in a clean, predictable descent. No spikes, no erratic behavior. The model was taking smaller, more precise steps toward the minimum.
The Overfitting Signal
The second run also revealed something important: by epoch 15, training loss had dropped to 0.0285 while validation loss sat at 0.0718 — a 2.5x gap. The model was starting to memorize training examples rather than learning generalizable features.
This makes sense. The network has no regularization — no dropout, no weight decay, no data augmentation. With ~243,000 trainable parameters and 60,000 training images, there’s enough capacity to overfit.
The validation loss was still decreasing at epoch 15, so the model hadn’t fully overfit yet. But the widening gap between training and validation loss is the early warning sign. Left unchecked, validation loss would eventually plateau or rise while training loss continued to drop.
The Takeaway
The biggest lesson wasn’t about architecture — it was about learning rate. A 100x reduction in learning rate turned chaotic training into smooth convergence and improved accuracy. The loss curves from both runs are a clear visual demonstration of how much a single hyperparameter can affect training stability and final accuracy.
MNIST is often dismissed as a toy dataset, and it is. But building a simple model on a simple dataset and actually paying attention to the training dynamics teaches you things that get lost when you jump straight to complex architectures. You can see overfitting emerge in real time. You can watch learning rate change the shape of convergence. Every signal is clear because there’s nothing else to confuse it.
Sometimes the most valuable thing a project can teach you has nothing to do with the final accuracy number.
Stay in the loop
The occasional email when there's something new worth sharing.